
價格:免費
更新日期:2019-11-21
檔案大小:186.6 MB
目前版本:1.07
版本需求:OS X 10.7 或以上版本,64 位元處理器

PDF Text OCR Xtractor recognises and extracts text from PDF files and digital image documents with support to 19 different languages. It turns images into editable text.
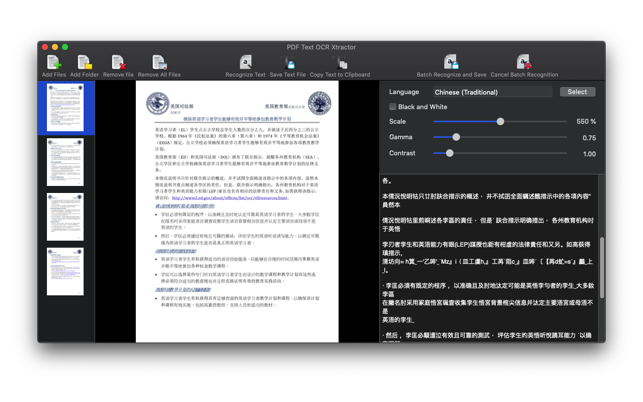
PDF Text OCR Xtractor allows you to turn scanned documents including PDFs and digital images into editable and searchable text content.
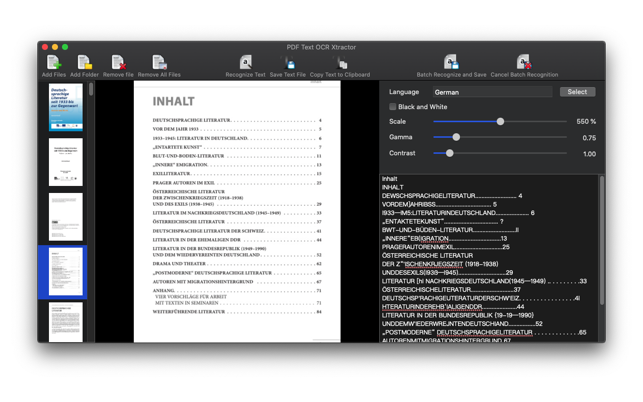
PDF Text OCR Xtractor uses advanced OCR technology (Optical Character Recognition) to recognise characters on digital images and PDF pages and turn them into editable text content you can save to disk or copy to the clipboard.

Languages supported by PDF Text OCR Xtractor are: English, Chinese (Simplified), Chinese (Traditional), Danish, German,
Finnish, French, Hebrew, Hungarian, Italian, Japanese, Korean, Dutch, Norwegian, Polish, Portuguese, Russian, Spanish, and Swedish.